
说到计算广告,或者个性化推荐,甚至一般的互联网产品,无论是运营、产品还是技术,最为关注的指标,就是点击率。业界也经常流传着一些故事,某某科学家通过建立更好的点击率预测模型,为公司带来了上亿的增量收入。点击率这样一个简单直接的统计量,为什么要用复杂的数学模型来刻画呢?这样的模型又是如何建立与评估的呢?我们这一期就来谈谈这个问题。
一、为什么要建立一个点击率模型?
无论是人工运营还是机器决策,我们都希望对某条广告或内容可能的点击率有一个预判,以便判断哪些条目应该被放在更重要的位置上。这件事儿看起来并不难,比如说我有十条内容,在历史上呈现出来的点击率各个不同,那么只需要根据历史点击率的统计做决策即可,似乎并没有什么困难。
然并卵。直接统计历史点击率的方法,虽然简单易操作,却会碰到一个非常棘手的问题。首先,大家要建立一个概念:不考虑位置、时间等一系列环境因素,绝对的点击率水平是没有什么太大意义的。比方说,下面的一个广告,分别被放在图中的两个位置上,统计得到前者的点击率是2%,后者的点击率是1%,究竟哪个广告好一些呢?其实我们得不出任何结论。
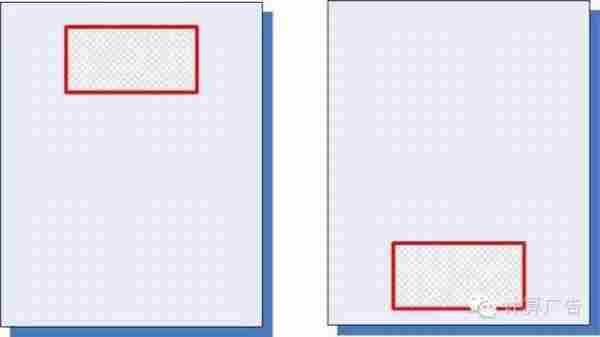
于是,聪明的运营想到一个办法,干脆我在不同的位置上分别统计点击率,然后分别排序。这个思路从道理上来说无懈可击,相当于直接求解联合分布;不过,其实用价值并不高:在每个位置上分别统计,大多数广告或内容条目的数据都太少,比如说100次展示,产生了一次点击,这难道能得出1%点击率的结论么?
那能不能再换一个思路,找到一些影响点击率的一些关健因素,对这些因素分别统计?这实际上已经产生了“特征”这样的建模思路了。比如说,广告位是一个因素,广告本身是一个因素,用户的性别是一个因素,在每个因素上分别统计点击率,从数据充分性上是可行的。不过这又产生了一个新的问题:我知道了男性用户的平均点击率、广告位S平均点击率、某广告A的平均点击率,那么如何评估某男性用户在广告位S上看到广告A的点击率呢?直觉的方法,是求上面三个点击率的几何平均。不过这里面有一个隐含的假设:即这三个因素是相互独立的。然而当特征多起来以后,这样的独立性假设是很难保证的。
特征之间独立性,经常对我们的结论影响很大。比如说,中国的癌症发病率上升,到底是“中国”这个因素的原因呢?还是“平均寿命”这个因素的原因呢?显然这两个因素有一些相关性,因此简单的分别统计,往往也是行不通的。
那么怎么办呢?这就要统计学家和计算机科学家出马,建立一个综合考虑各种特征,并根据历史数据调整出来的点击率模型,这个模型既要考虑各种特征的相关性,又要解决每个特征数据充分性的问题,并且还要能在大量的数据上自动训练优化。这就是点击率模型的意义,这是一项伟大的、光荣的、正确的、有着极大实用价值和战略意义的互联网+和大数据时代的重要工作。那位说了,有必要抬得这么高么?当然有必要!因为这门手艺我也粗通一点儿,不吹哪行。
二、怎样建立一个点击率模型?
这个问题比较简单,我们就不多谈了。(想骂街的读者,请稍安勿躁,继续往下看。)
三、如何评估一个点击率模型?
评估点击率模型的好坏,有各种定性的或定量的、线上的或线下的方法。但是不论什么样的评测方法,其本质都是一样,就是要看这个模型区别被点击的展示与没被点击的展示之间的区别。当然,如果能找到一个离线可以计算的量化指标,是再好不过了。
这样的指标是有一个,就是如下图所示的ROC曲线下的面积,术语上称为AUC。(关于ROC和AUC的详细介绍,请大家参考《计算广告》第*章。)AUC这个数值越大,对应的模型区别能力就越强。
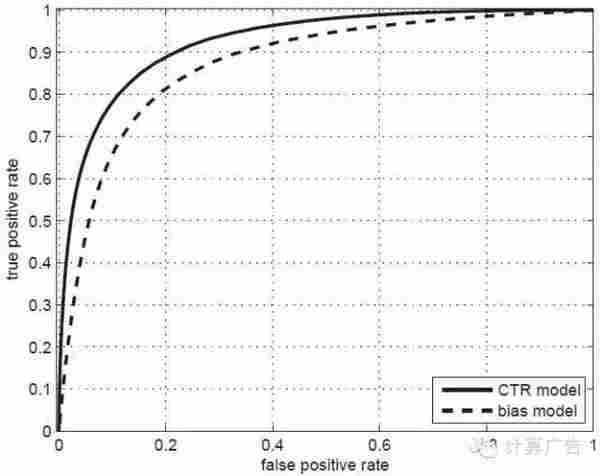
好了,为了让大家深入理解点击率模型评测的关键,我们要谈到一个常见的口水仗:有一天,有两位工程师在闲谈,一位叫小优,一位叫小度。他们分别负责某视频网站和某网盟广告的点击率建模。小优说:最近可把我忙坏了,上线了个全新的点击率模型,把AUC从0.62提高到0.67,效果真不错!哪知道小度听了哈哈大笑:这数据你也好意思拿出来说,我们的AUC早就到0.9以上了!
那么,是不是小度的模型比小优真的好那么多呢?当然不是,我们看看该视频网站和网盟的广告位分布,就一目了然了。
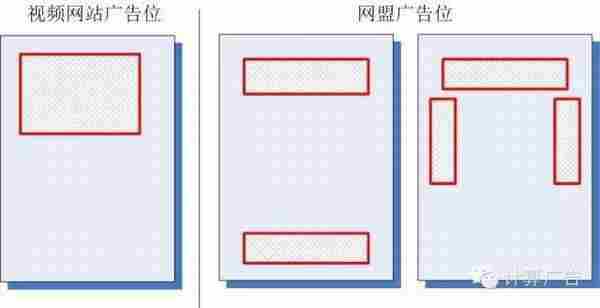
什么?你还没有明白,那么我建议你自己好好把这个问题想清楚。不论你是运营还是产品,经过了这样的思考,你的数据解读能力会上一个台阶。
好了,三个关键点说完了,我知道有的读者还会对第二点表示没看懂,那干脆我们就再多说一点儿,将2015年11月15日王超在计算广告读者微信群里所做的题为“点击率预估趋势浅析”的分享内容整理发布在下面。没有坚持到这里就把文章关掉的码农们,让他们后悔一辈子去吧!
今天分享一下点击率预估近年来的一些趋势。主要结合刘鹏老师的一些指导,以及自身工作的一些经验,有偏颇的地方请大家多多指正。
在计算广告第一版的书里,主要讲到了经典的点击率预估模型逻辑回归,特征工程,模型的评估等,相信对大多数场景来说这一步是必做的基线版本。后续可以在此基础上做一些更细致的特征工程和模型工作。考虑到群里的朋友都已经拿到了这本书,今天先跳过书里覆盖的内容,讲一些目前书里没有提及的部分。如果对书里内容还不够了解的朋友,建议第一步还是把书中基础性的内容仔细掌握。
LR+人工特征工程风光不再
讲近年来点击率预估的发展趋势,我想先从近年来一次最具参考意义和号召力的criteo举办的点击率预估比赛作为切入点说起。
为什么要拿这次比赛来说?首先criteo是全球一家专注在效果广告的公司,在业界很有影响力,计算广告书中对其也有介绍,比赛的数据质量不错。其次前三名有10w美金的激励,继KDD cup 2012 track2之后,算是点击率预估问题上最知名的一次比赛,很多kdd cup的往届冠军都前来参加。最后呢这次比赛都是脱敏过的特征,没有具体的特征含义,使得难以结合领域知识做更细致的特征工程,更多考量模型的工作,比较适合我们今天讨论的话题,另外比赛时间是从去年6月到9月三个月的时间,参赛者们的方案相对也会比较细致。
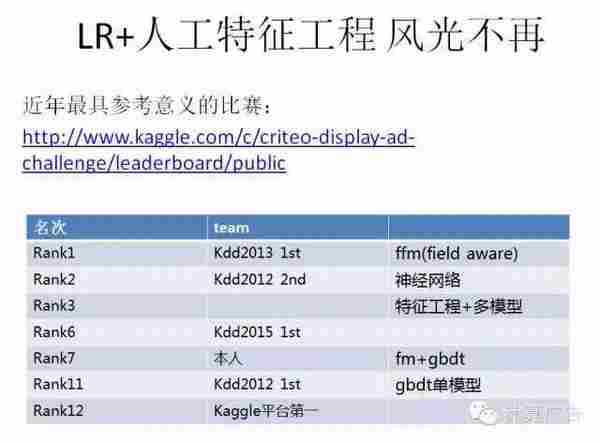
从leadboard中可以看到在700多支team里,Kdd 2012年起的各届冠军,这些比赛型的选手,基本占据了前十的位置,我是第7。其次,从使用的模型上,基本以fm和gbdt,还有神经网络这些非线性模型为主。可以这么说,在比赛里,逻辑回归加大量的人工特征工程的方案已经很难排到比赛前列,靠逻辑回归一个模型包打天下,已经成为过去时。
特征,特征

在接下来讲具体模型之前,先来回顾一下我们为什么要做大量的特征工程。点击率预估的主要场景,是在各种长尾的流量上,对一个给定的<用户,广告,上下文>三元组做出精准估计。在这种long tail的场景下,用户或上下文对广告的偏好,基本都是一些相对weak的signal,我们需要把这些弱信号package在一起,才能去更好的发现当前场景下用户感兴趣的广告。
特征工程是各个公司相对模型来说更看重保密的部分,因为从其中会大致了解到该公司的数据分布,这方面的公开资料不会太多。大体来说,有这么俩部分工作:
首先了解行业的领域知识,去寻找和设计强信号依然重要,比如搜索广告里query和广告创意的相关性是强信号,电商领域图片和价格特征是强信号等。这部分工作是和各家公司业务紧密相关的。
其次如果采用的是逻辑回归这种广义线性模型,需要手动构造特征变换,才能更好处理非线性问题。常见的特征变换方法比如特征组合,特征选择,特征离散化归一化等,多数时候通过eyeballing和统计学的方法来完成。工程师自然是希望能将更多的精力放在设计业务上的强信号特征上面,而特征变换自动的由模型来完成。出于这样的考虑,非线性模型逐渐在取代LR,比如通过FM,GBDT去自动挖掘组合特征,通过GBDT去做特征选择,离散化等,正如上述比赛中看到的。
最后基于一些深度学习的方法,也能够做一些特征发现的事情,举个典型的例子就是语音识别里,dnn已经把MFCC这种人工特征取代了,wer有显著
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]