DDR爱好者之家 Design By 杰米
有严重者,甚至能侵害版权。那么这么庞大的信息,搜索引擎蜘蛛是怎么做到的呢?做网站seo的朋友一定要熟知这方面的知识,只有找对了问题的所在,才能突破收录排名局限!请先看一下图片吧。 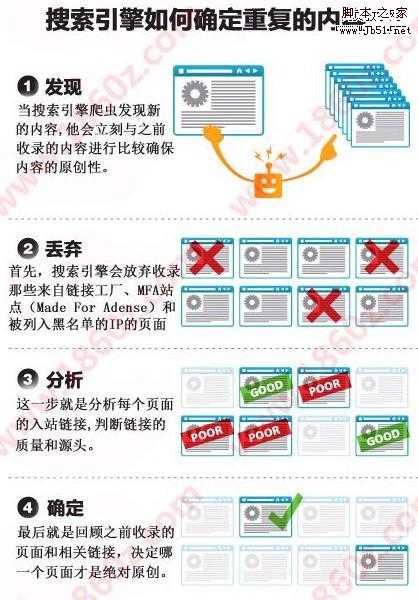
相信大家都能看懂图片的含义吧,比较生动一点,下面简单的给大家表述一下这四个步骤。
1.发现内容:当搜索引擎爬虫发现新内容的时候,他就会理科与之前收录的内容进行比较,确保网站的内容原创性!这一步很关键。如果是伪原创内容的话,请一定保证80%以上的不同!
2.信息丢弃:首先搜索引擎会放弃收录那些来自连接工厂,mfa站点(made for adense)和被列入黑名单的ip页面。
3.链接分析:这一步就是分析每个页面的入站链接,判断链接的质量和源头。这一步也是做导入链接的关键部分,在有限的时间内,做好高质量的链接,保证数量!
4.最后确定:最后就是回顾之前收录的页面和相关链接,决定哪一个页面才是绝对原创。并把原创内容放到排名前面。
总结,这里虽然设计的有的原创,有的伪原创,也有的可能是直接转载。百度蜘蛛和Google机器人默认的排名是最开始的创始地点。最原始的排名越靠前!
DDR爱好者之家 Design By 杰米
广告合作:本站广告合作请联系QQ:858582 申请时备注:广告合作(否则不回)
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
DDR爱好者之家 Design By 杰米
暂无评论...
更新日志
2025年12月19日
2025年12月19日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]