百度中文分词算法:指搜索引擎为了更好的辨别用户的需求,并且为了快速提供给用户需求性信息而使用的算法。
搜索引擎要在单位时间内处理千万亿级的页面数据量,因此搜索引擎拥有一个中文词库。比如百度现在大约有9万个中文词,那么搜索引擎就可以对千亿级的页面进行分析,按照中文词库进行了分类。
百度分词基本有三种分法
1、基于理解:傻瓜式匹配,小于等于3个中文字符百度是不进行切词的,比如搜索“大学堂”。
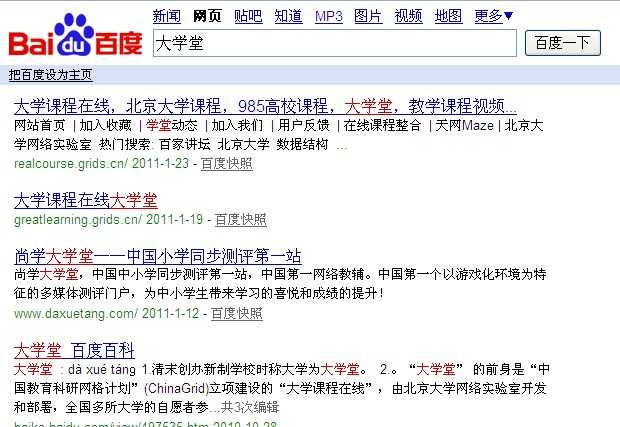
2、基于统计:百度把一个词标红的原因:标红的词一般是一个关键词,你搜索“学”字的时候,百度它自认的把“学习”也当成了一个关键词,所以出现“学习”这个词标红,这就是百度分词法:基于统计分词。
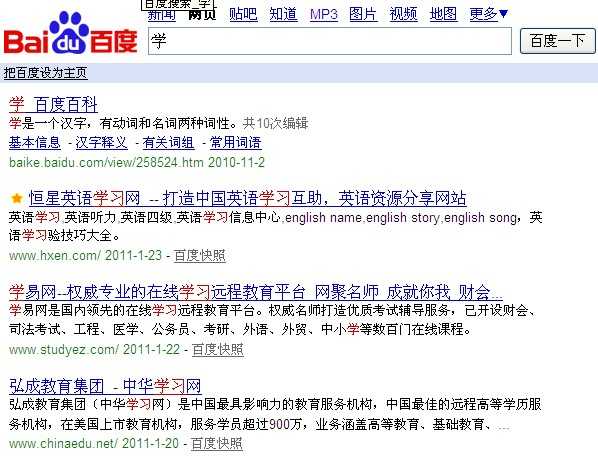
3、基于字符串匹配(百度的分词法:正向最大切词法)
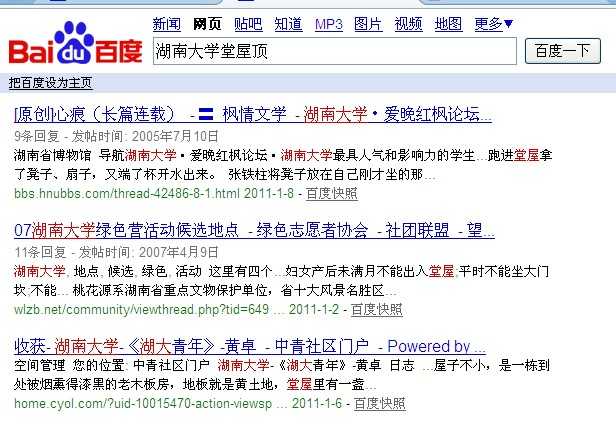
最大与最小(最大匹配:一直匹配到没词可配;最小匹配:匹配出词了就停止匹配,再从另一个词开始匹配)比如:百度搜索“湖南大学堂屋顶”,百度的一个分词算法我们把它当成一个黑盒子,我们通过一些输入关键词,根据百度的输出结果来判定百度的分词算法。正向与反向(正向:从前往后配;反向:从后往前配)(湖南大学堂屋顶)正向分法:湖南大学 堂屋 顶 (刘强大地方法)正向分法:刘 强大 地方 法。反向分法:方法 大地 刘 强。而在这个词语当中“大地”不是一个词。
另外,切词原理:百度有专有词库(是不可分割的)比如杰出人物(如:毛泽东)明星(如:刘德华)检索量大的词(如:买票难) 。
当然这些只是百度中文分词原理的一部分,也不是全对。因为百度算法是不可能透露出来,商业机秘如果让你知道,那岂不是有N多的百度了。
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
RTX 5090要首发 性能要翻倍!三星展示GDDR7显存
三星在GTC上展示了专为下一代游戏GPU设计的GDDR7内存。
首次推出的GDDR7内存模块密度为16GB,每个模块容量为2GB。其速度预设为32 Gbps(PAM3),但也可以降至28 Gbps,以提高产量和初始阶段的整体性能和成本效益。
据三星表示,GDDR7内存的能效将提高20%,同时工作电压仅为1.1V,低于标准的1.2V。通过采用更新的封装材料和优化的电路设计,使得在高速运行时的发热量降低,GDDR7的热阻比GDDR6降低了70%。
更新日志
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]